

Writing fast (and butt-ugly) PRT code – speed up indicators
Viewing 10 posts - 1 through 10 (of 10 total)
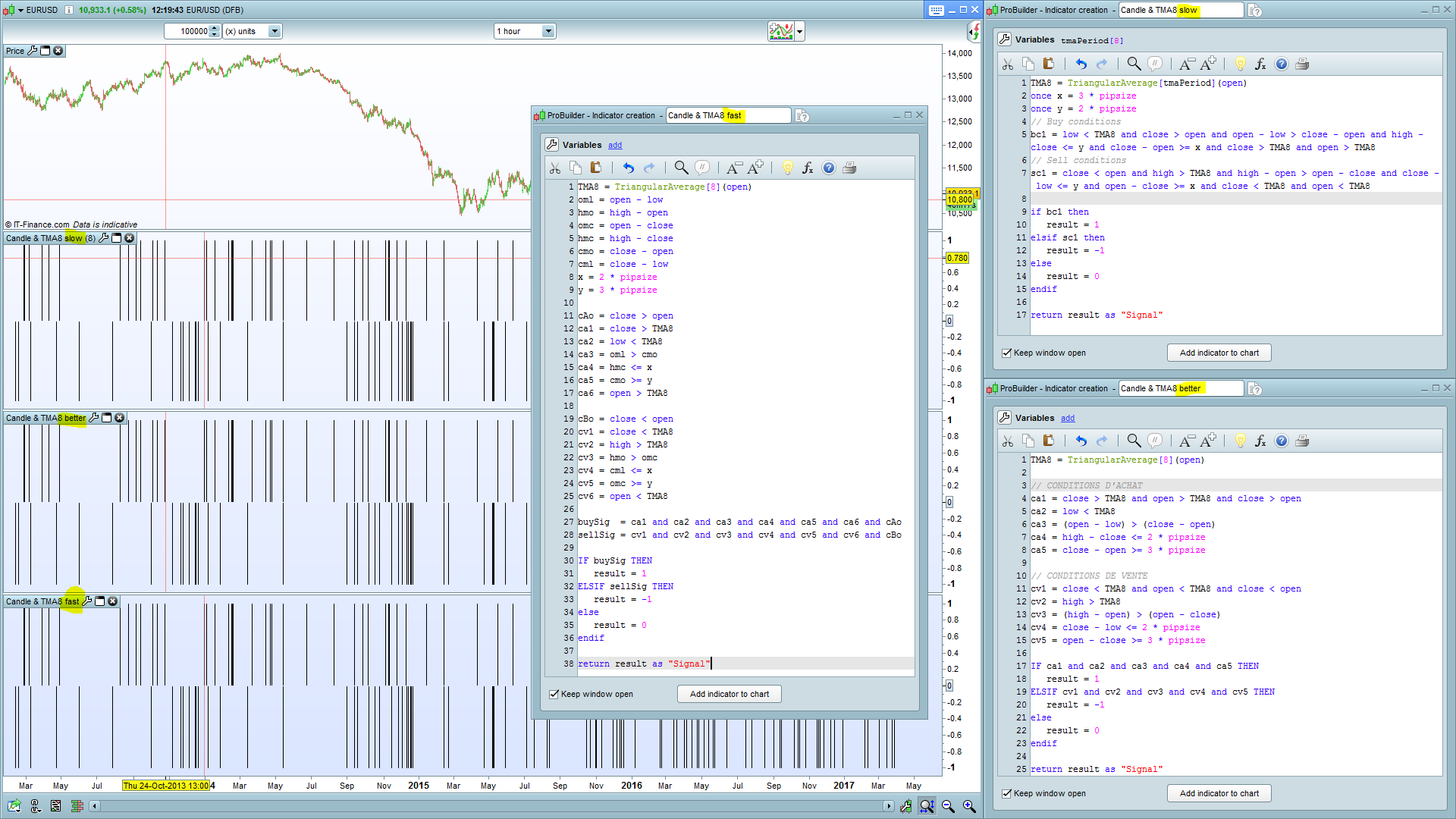
Viewing 10 posts - 1 through 10 (of 10 total)
- You must be logged in to reply to this topic.
New Reply
Summary
This topic contains 9 replies,
has 1 voice, and was last updated by ![]()
1 year, 5 months ago.
Topic Details
| Forum: | ProOrder: Automated Strategies & Backtesting |
| Language: | English |
| Started: | 04/28/2017 |
| Status: | Active |
| Attachments: | 2 files |
Loading...